Intro to Deep Learning
Deep learning has revolutionized the way computers learn and process information. It has become one of the most powerful tools for complex data analysis and automated decision-making. As a subfield of artificial intelligence (AI) and machine learning (ML), deep learning uses artificial neural networks (ANNs) to extract patterns and insights from large amounts of data autonomously.
Artificial neural networks (ANNs) have been around for several decades, but recent advances in ANN architecture and training methods have driven a surge in their popularity and applications. This progress is fueled by:
Computing Power: The accessibility of GPUs and TPUs (Tensor Processing Units) has accelerated the training process, enabling efficient processing of high-dimensional data as well as the development of models with millions (or billions) of parameters.
Development of DL Frameworks: Tools like TensorFlow and PyTorch have made it easier to build and train neural networks and are optimized for GPU and TPU performance.
Big Data: Expanding datasets, such as the Protein Data Bank (PDB) (containing >200,000 protein structures), have enabled the training of larger and more complex models, such as AlphaFold2 [1], whose creators were awarded the 2024 Nobel Prize in Chemistry.
Originally proposed in 1943 to help researchers understand brain function [2], ANNs now serve as powerful tools for learning from data and solving complex problems.
Deep Learning in Life Sciences
Deep learning is driving breakthroughs in life sciences research, including:
The range of deep learning applications is extensive, making it an exciting field for researchers to explore.
By the end of this section, you should be able to:
Describe the components of a perceptron
Mathematically define the sigmoid, softmax, and ReLU activation functions
Implement various activation functions in Python
Describe the basic neural network architecture
Define training and inference phases of deep learning
Understanding Neural Networks
Artificial Neural Networks, or just neural networks for short, are the backbone of deep learning. They consist of artificial neurons called perceptrons, which process information in a way inspired by biological neurons in the human brain.
In biological neurons, the dendrite receives electrical signals from other neurons and only fires an output signal when the total input signals exceed a certain threshold. Similarly, perceptrons take in multiple inputs, apply weights to them to signal their importance, and produce a single output that represents the total strength of the input signals.
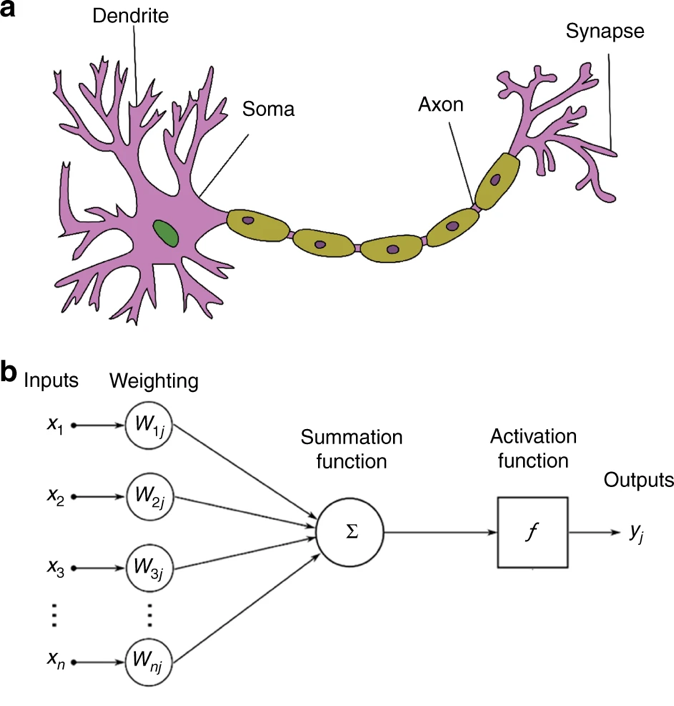
Biological neuron (a) vs. artificial neuron (b). Source: Zhang et al. 2019 [3]
Perceptrons: The Building Blocks of Neural Networks
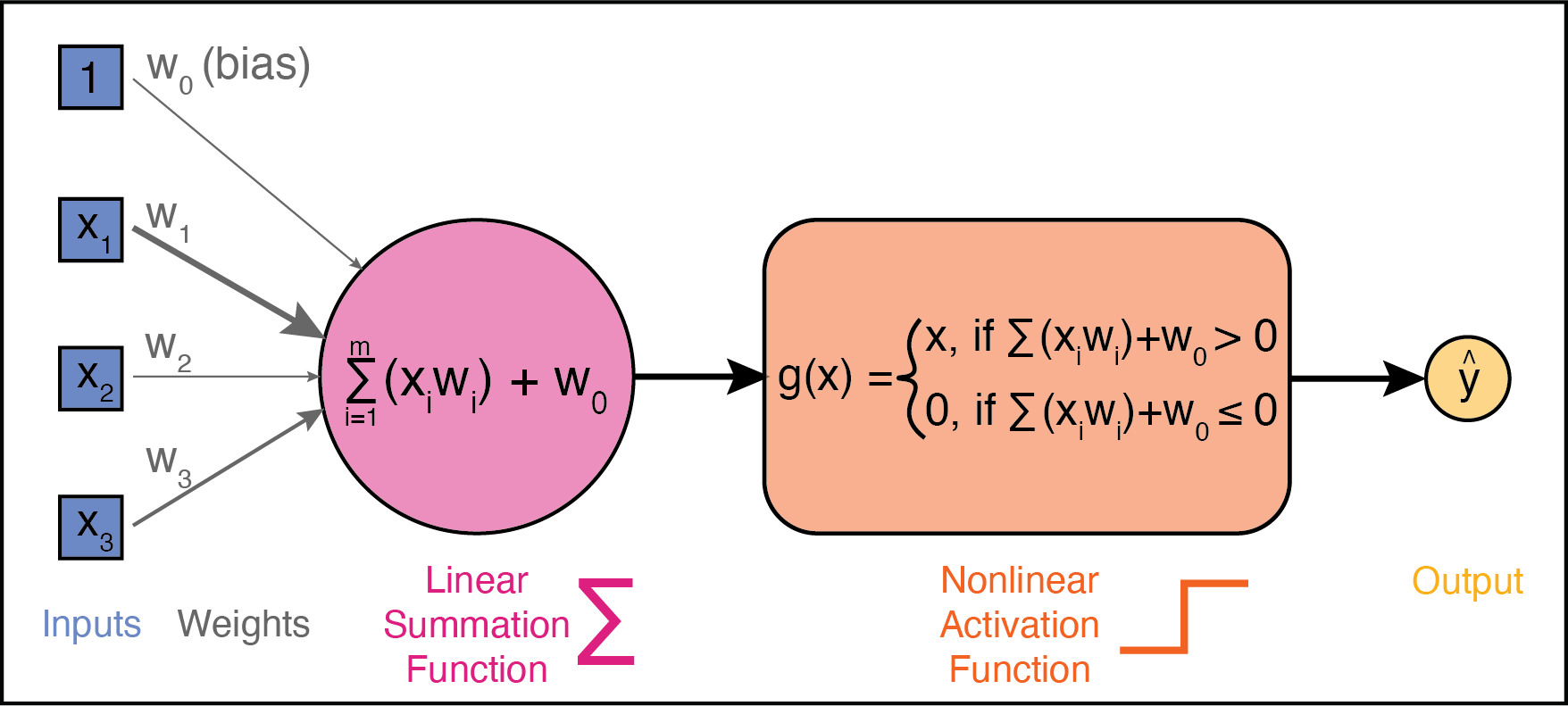
1. Inputs and Weights
A perceptron has multiple inputs, which we’ll call \(x_1\), \(x_2\), and \(x_3\). Each input has an associated weight, denoted as \(w_1\), \(w_2\), and \(w_3\). These weights determine how important each input is to the perceptron’s decision. During training, these weights are adjusted to improve accuracy; during testing, they remain fixed.
2. Linear Summation Function
Each input is multiplied by its corresponding weight, and then all of the weighted inputs are summed together via a linear summation function:
\[Sum = (w_1x_1) + (w_2x_2) + (w_3x_3) + w_0\]
A bias term, \(w_0\), is also added to the linear combination. The bias is like the intercept in a linear equation–it allows the perceptron to make predictions even when all inputs are zero. Together, the weights and bias (\(w_0, w_1, w_2,...\)) are called the parameters of the perceptron.
3. Nonlinear Activation function
The weighted sum (including the bias) is then passed through a nonlinear activation function to produce the perceptron’s output. Activation functions introduce non-linearity, allowing neural networks to learn complex patterns in data.
The basic architecture of a perceptron is depicted below:
Activation Functions
Activation functions are the critical components that give neural networks their power to learn.
Without them, neural networks would be limited to learning only linear relationships. Most real-world problems are far more complex than this, and activation functions introduce this essential non-linearity.
You can think of activation functions like switches that decide if and how strongly a neuron “fires” based on its inputs. They also transform incoming signals into outputs in non-linear ways. Different activation functions behave differently, and understanding them is key to choosing the right one for your task.
Let’s explore three key activation functions through hands-on examples to develop intuition about how they work.
The sigmoid Activation Function
The sigmoid function takes any number and “squashes” it into a value between 0 and 1. That makes it perfect for representing probabilities.
Mathematically, the sigmoid function is defined as:
Python Hands-On: Visualizing Sigmoid
Let’s code our own sigmoid function and see how it transforms different inputs.
Step 1: Define the sigmoid function
>>> import numpy as np
>>> # Define the sigmoid function
>>> def sigmoid(x):
>>> return 1.0 / (1 + np.exp(-x))
Step 2: Generate inputs and plot the function
>>> import matplotlib.pyplot as plt
>>> # Create 100 x-values evenly spaced between -10 and 10
>>> x = np.linspace(-10, 10, 100)
>>> # Apply the sigmoid function to each x-value
>>> y = sigmoid(x)
>>> # Plot the results
>>> plt.plot(x, y)
>>> plt.xlabel("x")
>>> plt.ylabel("Sigmoid(x)")
>>> plt.title("Sigmoid Activation Function")
>>> plt.show()
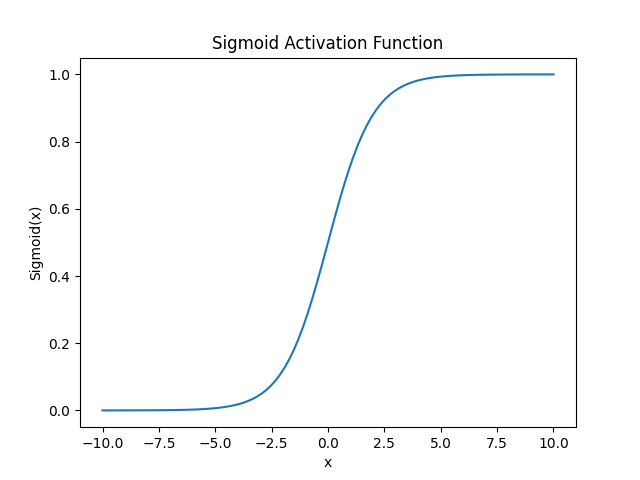
Key Properties of Sigmoid:
Bounded Output: The
sigmoidfunction always outputs values between 0 and 1, making it ideal for representing probabilities.S-shaped Curve: Around the midpoint (x=0), small changes in input produce the largest changes in output. This is where the neuron is most responsive to its input.
Saturates at Extremes: At the extremes of the curve, the function becomes very flat, meaning that large changes in input produce only tiny changes in output.
In Neural Networks: Sigmoid is often used in the output layer of a neural network when you’re solving a binary classification problem (e.g., “Is this image a cat?” → 0.92 means “92% confident it’s a cat”).
The softmax Activation Function
The softmax function is often used in the output layer of a neural network when you have more than two classes.
It turns a list of numbers (a vector) into a probability distribution:
All output values are between 0 and 1
All outputs sum to 1
The largest value in the input vector gets the highest probability
Mathematically, for a vector \(z = [z_1, z_2, ..., z_n]\), the softmax of element \(i\) is defined as:
Python Hands-On: Exploring Softmax
Let’s see how softmax turns raw scores into probabilities across multiple classes.
Step 1: Define the softmax function
>>> import numpy as np
>>> def softmax(z):
>>> # Calculate e^(z_i) for each element in z
>>> exps = np.exp(z)
>>> # Divide each exponential by the sum of all exponentials
>>> return exps / np.sum(exps)
Step 2: Generate inputs and plot the function
>>> # Example 1: Increasing values
>>> print("softmax([1, 2, 3]) ->", softmax(np.array([1, 2, 3])))
>>> # Example 2: Identical values
>>> print("softmax([3, 3, 3]) ->", softmax(np.array([3, 3, 3])))
>>> # Example 3: One dominant class
>>> print("softmax([10, 0, 0]) ->", softmax(np.array([10, 0, 0])))
This code will output:
softmax([1, 2, 3]) -> [0.09003057 0.24472847 0.66524096]
softmax([3, 3, 3]) -> [0.33333333 0.33333333 0.33333333]
softmax([10, 0, 0]) -> [9.99909208e-01 4.53958078e-05 4.53958078e-05]
Key Properties of Softmax:
Probability Distribution: Outputs sum to exactly 1.0
Preserves Ranking: Highest input gets highest probability
Relative Differences Matter: Amplifies differences between inputs
In Neural Networks: Softmax is used in the output layer for multi-class classification problems, like identifyig which animal species (cat, dog, bird) is in an image.
The ReLU Activation Function
The ReLU (Rectified Linear Unit) function is the most widely used activation function in modern neural networks, especially for hidden layers.
Mathematically, the ReLU function is defined as:
This means:
If the input is positive, the output is as-is
If the input if negative or zero, output is 0
Python Hands-On: Visualizing ReLU
Let’s implement and explore the ReLU activation function.
Step 1: Define the ReLU function
>>> import numpy as np
>>> # Define the ReLU function
>>> def relu(x):
>>> return np.maximum(0, x)
Step 2: Generate inputs and plot the function
>>> import matplotlib.pyplot as plt
>>> # Create 100 x-values evenly spaced between -10 and 10
>>> x = np.linspace(-10, 10, 100)
>>> # Apply the ReLU function to each x-value
>>> y = relu(x)
>>> # Plot the results
>>> plt.plot(x, y)
>>> plt.xlabel("x")
>>> plt.ylabel("ReLU(x)")
>>> plt.title("ReLU Activation Function")
>>> plt.show()
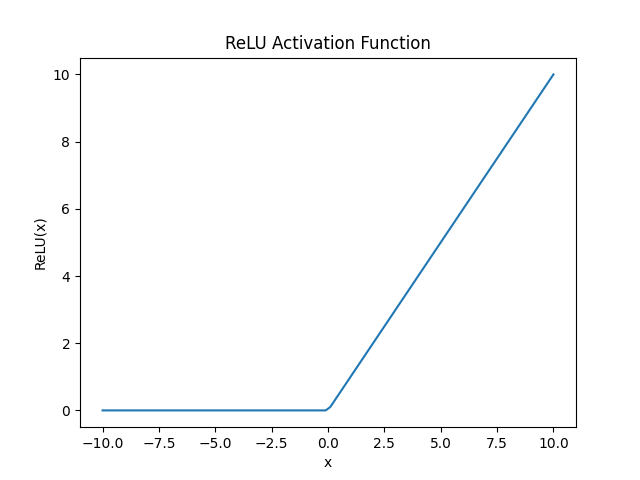
Key Properties of ReLU:
Fast Computation: The
ReLUfunction just returns 0 or the input, making it easy to compute.Sparse Activation: Only perceptrons with positive inputs are activated, making the network sparser and more efficient.
No Upper Bound: Unlike sigmoid, ReLU can output any positive value, which allows for more flexibility in the network’s output range.
In Neural Networks: ReLU is most commonly used in the hidden layers of deep neural networks because it helps the network learn quickly and efficiently by only activating neurons when they have a positive input.
Function |
Output Range |
Best Used For |
Key Advantage |
|---|---|---|---|
Sigmoid |
0 to 1 |
Binary classification outputs |
Outputs interpretable as probabilities |
Softmax |
0 to 1 (sum = 1) |
Multi-class classification outputs |
Creates a probability distribution |
ReLU |
0 to infinity |
Hidden layers |
Fast computation, no saturation for positive values |
Network Architecture
A neural network is made up of layers of perceptrons, where each perceptron applies a mathematical function to its inputs and passes the result to the next layer. These layers include:
Input layer: The first layer of the neural network, which receives raw data (e.g., an image or DNA sequence).
Hidden layers: Layers between the input and output layers, which learn complex features from the input data.
Output layer: The final layer of the neural network, which produces the final output (e.g., classification of a tumor as malignant or benign).
The basic architecture of a neural network is depicted below:
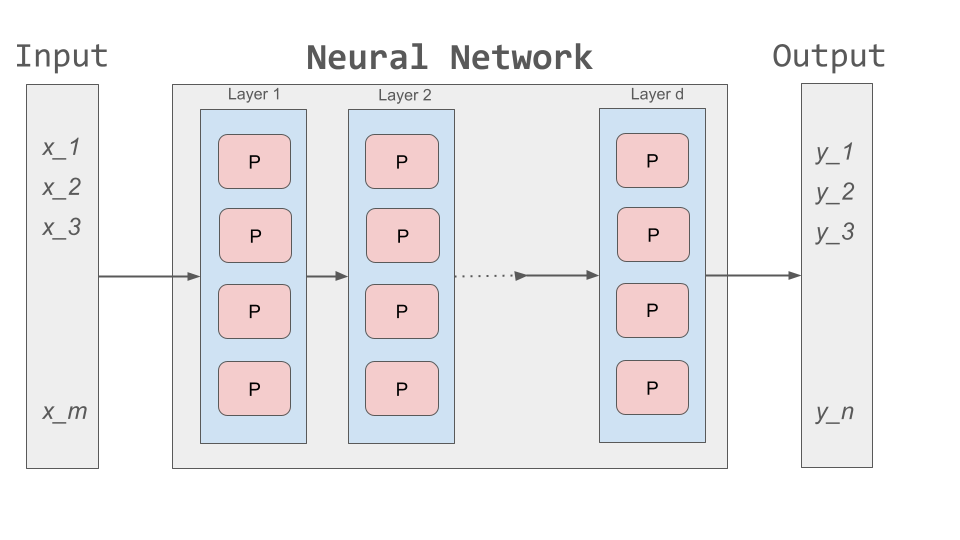
Each perceptron in a layer is connected to perceptrons in the next layer, and these connections have weights, which determine the influence of each input. During training, these weights are adjusted to improve accuracy.
Putting it all Together
To summarize, the perceptron takes in multiple inputs (as many as you want) and assigns weights to them. It calculates a weighted sum of the inputs, adds a bias term, and then passes the result through an activation function to produce an output. When multiple perceptrons are connected, they form a neural network that can learn complex decision boundaries.
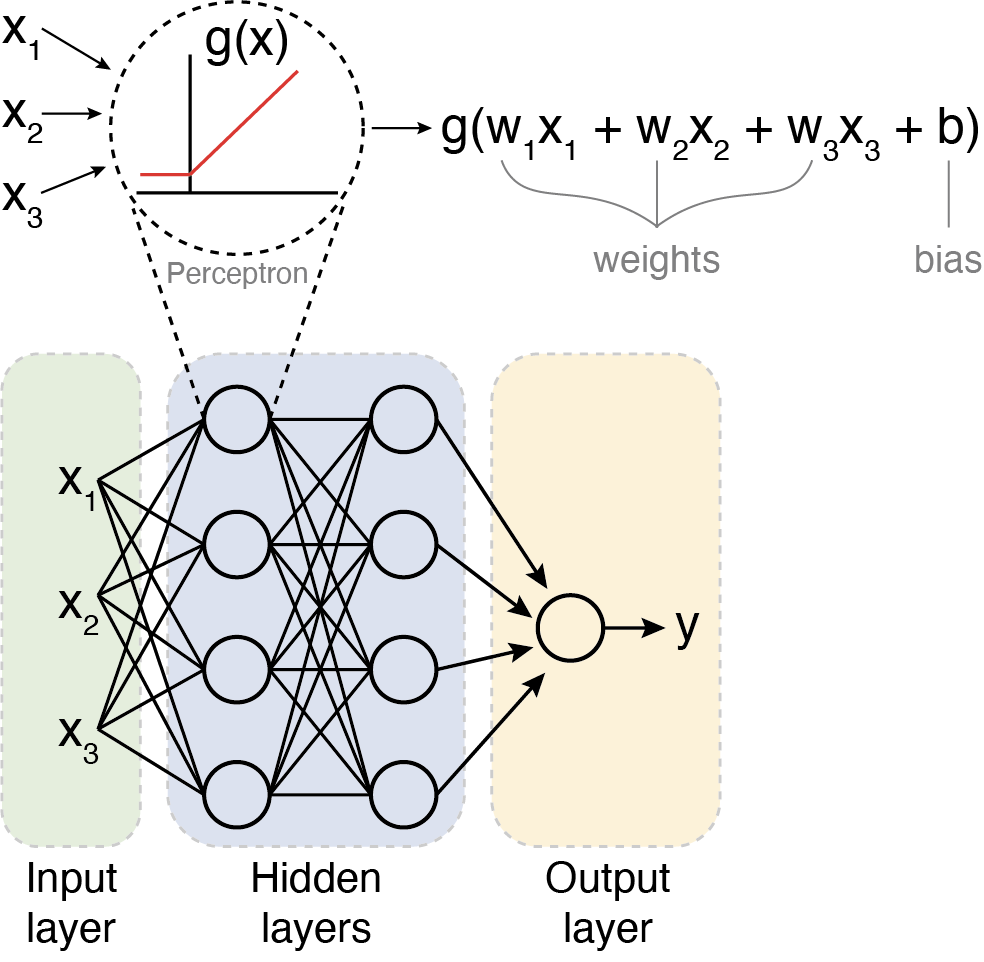
Multilayer perceptron. Adapted from: Beardall et al. 2022 [4]
Training and Inference
Deep learning involves two main phases: training and inference. Broadly speaking, training involves multiple iterations of feeding data into a neural network and adjusting its parameters to minimize prediction errors. This process requires large amounts of data and computational resources to fine-tune the model for accuracy. Once trained, the model enters the inference phase, where it applies its learned knowledge to new, unseen data to make predictions.
Training
How do we choose values for the parameters (i.e., the \(w_0, w_1, ..., w_n\) in each perceptron) to make a neural network accurately predict an outcome?
Start with random weights: At first, the model’s predictions are guesses and likely to be inaccurate.
Compare predictions to true labels: Since the training data is labeled, we can compare the model’s predictions to the actual labels (by calculating the error).
Adjust weights using gradient descent: The model iteratively updates its parameters to minimize the error, improving its predictions over time.
Gradient Descent: A Brief Refresher
Imagine you are hiking down a mountain in thick fog. Your goal is to reach the bottom of the valley as quickly as possible. But because of the fog, you can only see a few feet in front of you. So, you take small steps downhill, always moving in the steepest direction based on what’s directly in front of you. This is pretty much how gradient descent works in machine learning. Let’s quickly break it down using this image as a guide:
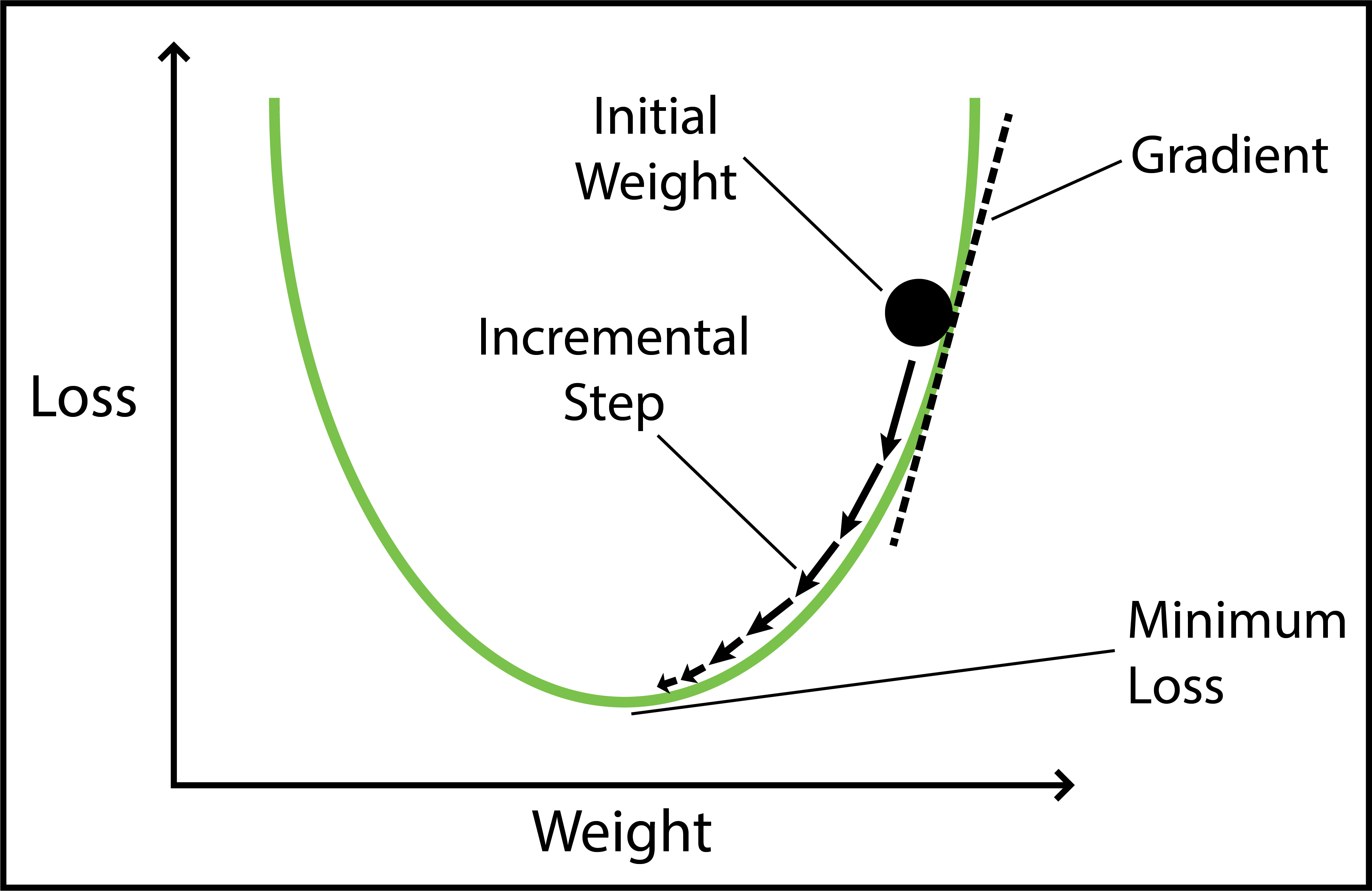
Loss (y-axis) = The height of the mountain: The higher you are, the worse your model is performing.
Weight (x-axis) = Your position on the mountain: Different positions on the mountain correspond to different weight values. The goal of training is to find the weight that gives the Minimum Loss.
Initial Weight = Your starting position on the mountain: This is where you start hiking from (a random weight value). At this point, your model isn’t very accurate (it has high loss).
Gradient = The slope of the mountain at your current position:
If the slope is steep, you take bigger steps (faster learning). If the slope is gentle, you take smaller steps (slower learning) to avoid overshooting the minimum.
If the slope is negative, you move right (increase weight). If the slope is positive, move left (decrease weight).
Minimum Loss = The bottom of the valley: This is the point where we have reached the optimal weight value. Our model is now performing the best it can.
Gradient descent helps adjust weights, but in multi-layer networks, we need a way to distribute these adjustments across all layers. This process is called backpropagation, and it allows error signals to flow backward through the network, updating weights efficiently.
Now that we have a basic understanding of how neural networks adjust their weights, let’s look at a real-world example: training a neural network to classify gene expression profiles as malignant or benign.
Training Example: Classifying Malignant vs Benign Tumors from Gene Expression
Imagine you are training a neural network to classify tumors as either malignant or benign based on its gene expression profile.
Each tumor sample is represented as a long vector of gene expression values–one value per gene.
Each input perceptron receives the expression level of a single gene. So, if your dataset includes 20,000 genes, the input layer will contain 20,000 perceptrons. Each one processes the expression level of a single gene.
Hidden layers learn to detect complex, nonlinear patterns by combining gene-level signals into higher-level features.
The final layer produces a prediction: malignant or benign
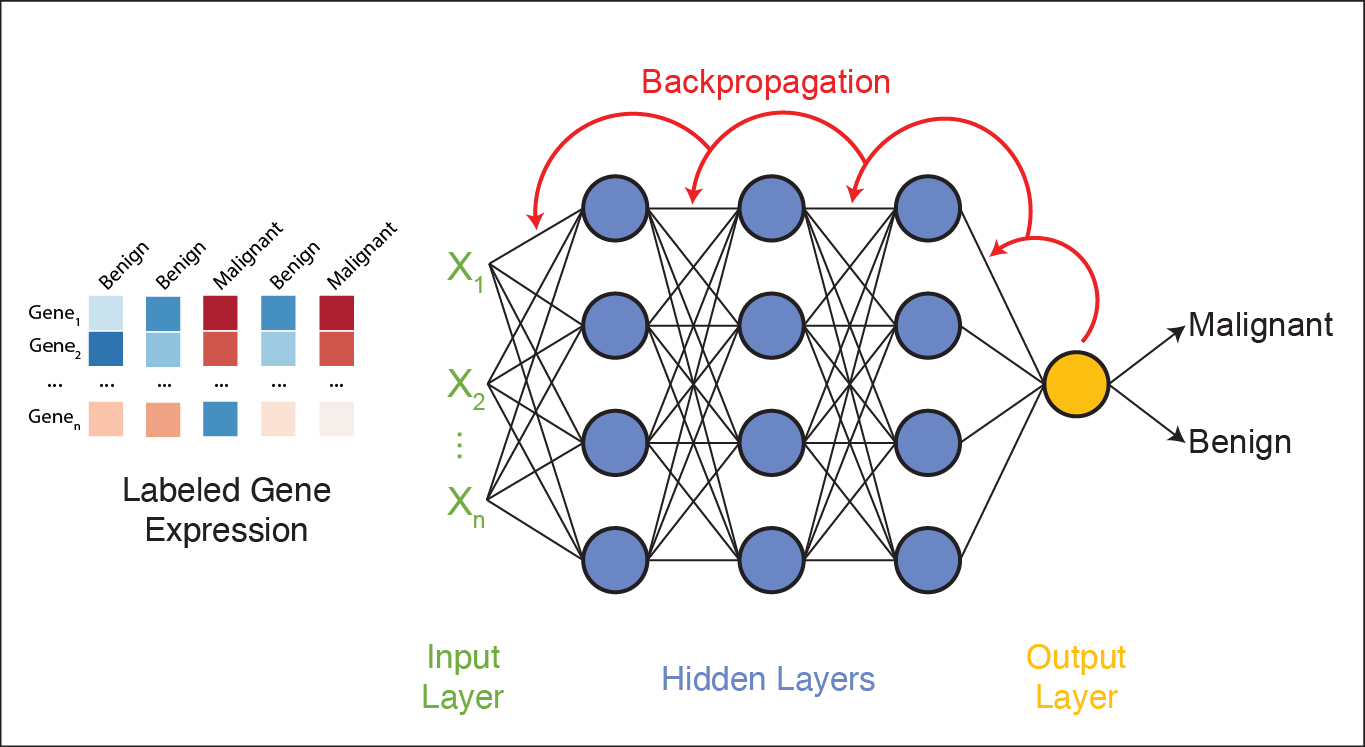
The network processes each gene expression profile through all layers and generates a prediction. If it gets the prediction wrong, an error signal is sent backward (backpropagation), and the weights are adjusted accordingly using gradient descent. This process continues across many training samples until the model learns a set of weights that minimizes prediction error.
Once training is complete, the model no longer updates its weights–it is ready to apply what it has learned to new, unseen data. This is where inference comes in.
Inference
Inference is the process of using a trained neural network to make predictions on new, unseen data. During inference, the model does not update its weights — it simply applies the learned weights to the new data to generate a prediction.
In our example, each new tumor sample is represented as a vector of gene expression values. This vector is fed into the trained network, which processes it through all layers using the learned weights and biases.
The network then produces a predicted classification: whether the gene expression profile indicates a malignant or benign tumor.
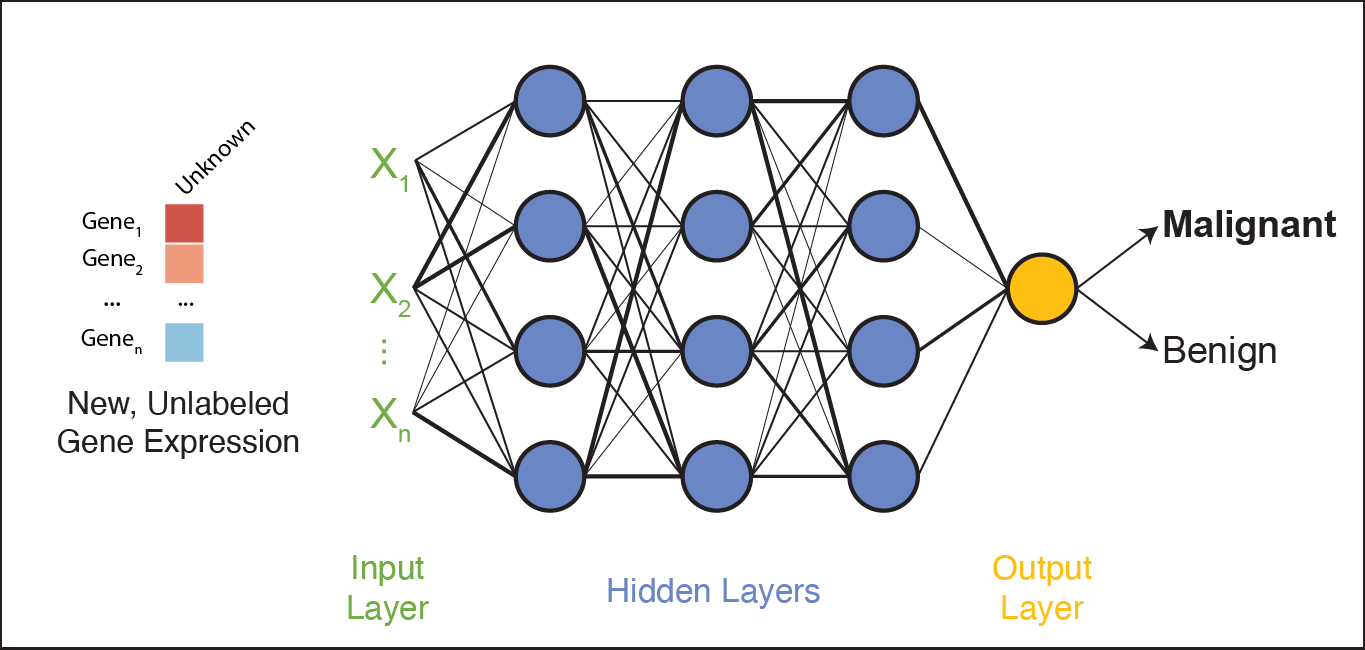
This is the stage where the neural network becomes practically useful: once trained, it can analyze and interpret new biological data to support tasks like diagnosis, prognosis, or treatment decision-making.
In the next session, we’ll apply these concepts hands-on by building our own neural network from scratch.
Additional Resources
This documentation is adapted from: COE 379L: Software Design For Responsible Intelligent Systems