Build Your Own Convolutional Neural Network
Coral reefs are among the most diverse and valuable ecosystems on Earth, providing habitat for 25% of all marine species and supporting the livelihoods of over half a billion people worldwide. However, these ecosystems face unprecedented threats from climate change, ocean acidification, and other human activities, with many species now endangered.
We are given a dataset containing images of three different coral species:
Acropora cervicornis (Staghorn Coral)
Colpophyllia natans (Boulder Brain Coral)
Montastraea cavernosa (Greater Star Coral)
Our task is to build a Convolutional Neural Network (CNN) that can classify the coral images into the correct species. This technology can help automate coral reef monitoring efforts and support conservation initiatives by enabling rapid, large-scale species identification.
By the end of this exercise, you should be able to:
Import, explore, organize, visualize, and pre-process input image data
Build and train a CNN from scratch
Build and train a CNN based on the VGG19 architecture (transfer learning)
Use callbacks to optimize the model performance during training
Assess model accuracy numerically (e.g. precision, recall, F1-score) and visually (e.g. confusion matrix)
Note
In this section, long blocks of Python code are shown with line numbers on the left-hand side. The Python code blocks can be run in a Jupyter Notebook, interactive Python interpreter, or in a stand-alone Python script:
1print('Hello, world!')
2# Python code here
Linux commands are shown with a host name in square brackets followed by a dollar sign. Linux commands should be entered into a Terminal:
[frontera]$ echo "Hello, world!"
Hello, world!
[frontera]$ # Linux commands here
Tutorial Setup and Materials
All materials and instructions for running this tutorial in the TACC Analysis Portal are available in our GitHub repository: TACC Deep Learning Tutorials.
Part 1: Building a CNN Model from Scratch
Step 0: Check GPU Availability and TensorFlow Version
Before training deep learning models, it’s important to check whether TensorFlow can access the GPU on your machine. Training on a GPU is significantly faster than on a CPU, especially for large image datasets.
If you’ve followed the setup instructions from Introduction to Systems and Data: Set up for Tutorials, you should now be running this notebook inside a containerized Jupyer kernel that includes:
TensorFlow v. 2.13.0 with GPU support
CUDA libraries compatible with the system
All required Python packages pre-installed
This cell will confirm that your environment is correctly configured (TIP: Make sure you change your kernel to Day3-tf-213).
1import tensorflow as tf
2
3# Check if TensorFlow can detect a GPU
4print("Num GPUs Available: ", len(tf.config.list_physical_devices('GPU')))
5
6# Print TensorFlow version
7print(tf.__version__)
8
9# Set random seed for reproducibility
10tf.random.set_seed(123)
You should see the following output:
Num GPUs Available: 4
2.13.0
Step 1: Data Loading and Organization
In this step, we load all coral images from the dataset directory and organize them into a DataFrame. Each image is assigned a label based on the name of the directory it’s stored in (i.e., ‘ACER’ - Acropora cervicornis, ‘CNAT’ - Colpophyllia natans, ‘MCAV’ - Montastraea cavernosa).
This DataFrame will serve as the foundation for splitting our data into training, validation, and test sets later in the tutorial.
1.1 List Dataset Directory Contents
Before loading the images, we first want to inspect the directory structure to make sure everything is in the right place.
Finding Your SCRATCH Directory Path:
On TACC systems, your scratch directory is a temporary storage space for computational work. To find the path to your scratch directory:
After logging into Frontera, run this command to see your SCRATCH path:
[frontera]$ echo $SCRATCH # This will output something like: /scratch1/12345/username
Verify that the coral-species dataset is in the correct location:
[frontera]$ ls $SCRATCH/tacc-deep-learning-tutorials/data/coral-species # You should see three directories: ACER, CNAT, and MCAV
Use the full path shown by these commands in the code below.
Now that you know your SCRATCH path, let’s list the contents of the coral-species data directory to verify that the subdirectories for each coral species are present and correctly named:
1from pathlib import Path
2
3# Define the path to the dataset directory
4# NOTE: Replace the path below with the full path to your scratch directory containing the training materials
5dataset_dir = Path('/scratch1/12345/username/tacc-deep-learning-tutorials/data/coral-species')
6
7# List the contents of the data directory
8print(list(dataset_dir.iterdir()))
You should see something like this:
[PosixPath('/scratch1/12345/username/tacc-deep-learning-tutorials/data/coral-species/CNAT'), PosixPath('/scratch1/12345/username/tacc-deep-learning-tutorials/data/coral-species/MCAV'), PosixPath('/scratch1/12345/username/tacc-deep-learning-tutorials/data/coral-species/ACER')]
1.2 Check File Extensions
Next, we scan the dataset directory and all its subdirectories to find out what types of image files are present. This helps us catch unexpected or unsupported file types (e.g., GIFs, txt files, etc.), which could cause problems later when loading images.
This also allows us to see if the images are all in the same format or not.
1# Recursively list all files under the dataset directory
2image_files = list(dataset_dir.rglob("*"))
3
4# Extract and print the unique file extensions
5# This helps us confirm that only valid image files are present
6extensions = set(p.suffix.lower() for p in image_files if p.is_file())
7print("File extensions found:", extensions)
Question: What file extensions are present in the dataset? Write down your answer.
1.3 Explore Image Dimensions and Color Modes
Before feeding images into a CNN, it’s important to understand the basic properties of the dataset. In this step, we examine the dimensions (width x height) as well as the color mode (e.g., RGB, RGBA, grayscale) of each image. This helps us decide if we need to resize or convert images before we begin training our CNN.
The script below prints a summary and gives recommendations if inconsistencies are found.
1from PIL import Image
2from pathlib import Path
3from collections import Counter
4
5def explore_image_dataset(dataset_dir):
6 """
7 Explore basic properties of images: size and color mode.
8 """
9 print("Starting image dataset exploration...\n")
10
11 # Gather all .jpg files in the dataset
12 image_files = list(Path(dataset_dir).rglob('*.jpg'))
13 print(f"Found {len(image_files)} image files\n")
14
15 # Track sizes and color modes
16 image_sizes = []
17 color_modes = []
18
19 print("Checking image dimensions and color modes...\n")
20 for img_path in image_files:
21 with Image.open(img_path) as img:
22 image_sizes.append(img.size)
23 color_modes.append(img.mode)
24
25 # Summarize image sizes
26 size_counts = Counter(image_sizes)
27 print("=== Image Sizes ===")
28 print(f"Found {len(size_counts)} unique image sizes:")
29 for size, count in size_counts.most_common():
30 print(f"- {size}: {count} images")
31
32 # Summarize color modes
33 mode_counts = Counter(color_modes)
34 print("\n=== Color Modes ===")
35 print(f"Found {len(mode_counts)} unique color modes:")
36 for mode, count in mode_counts.most_common():
37 print(f"- {mode}: {count} images")
38
39 # Simple recommendations
40 print("\n=== Recommendations ===")
41 if len(size_counts) > 1:
42 print(f"Images have different sizes. Consider resizing.")
43 else:
44 print("All images are the same size.")
45
46 if len(mode_counts) > 1:
47 print("Images have different color modes. Consider converting to RGB.")
48 else:
49 print("All images share the same color mode.")
50
51# Run the function
52explore_image_dataset(dataset_dir)
Our dataset analysis reveals some important characteristics that we’ll need to keep in mind as we proceed with the tutorial:
Image Size Variation: We have 417 total images in our dataset, with 63 different image sizes (dimensions). Also notice that some images are in portrait orientation (height > width) while others are landscape (width > height). CNNs expect all images to have the same dimensions, so we’ll need to resize them to a standard size before training our model.
Color Mode: All images share the same color mode. Great!
We will address these issues in Step 4 when we prepare our data for input into the CNN.
1.4 Check for Corrupted Images
Before continuing, we want to make sure that all images files are readable. Corrupted files can break your model training or cause unexpected errors during preprocessing.
In this step, we:
Attempt to open each ‘.jpg’ file using PIL
Discard any files that fail to load
This ensures we only keep clean, valid images for training.
1from PIL import Image
2from tqdm import tqdm
3
4# Find all .jpg files in the dataset
5# NOTE: add the correct file extension(s) for your image dataset in the space indicated below
6# TIP: see Step 1.2
7image_paths = list(dataset_dir.rglob('*.___'))
8
9# Create lists to store valid and corrupted files
10valid_images = []
11bad_images = []
12
13print("Checking for corrupted images...\n")
14
15# tqdm adds a progress bar to show how long the process will take
16for path in tqdm(image_paths):
17 try:
18 # Try to open and verify the image
19 with Image.open(path) as img:
20 img.verify()
21 # If the image is valid, add it to valid_images
22 valid_images.append(path)
23
24 except Exception:
25 # If any error occurs while opening/verifying the image, add it to bad_images
26 bad_images.append(path)
27
28print(f"Valid images: {len(valid_images)}")
29print(f"Corrupted images removed: {len(bad_images)}")
If there are any corrupted images in your dataset, this code will automatically remove them.
1.5 Create a DataFrame of Image Paths and Labels
Now that we have taken a peek at the format of our data and have removed any corrupted images, we can start setting up our data for training.
In this step, we build a pandas.DataFrame that organizes all the image data into two columns:
filepath: The full path to each image file
label: The class label for each image, taken from the directory name
This structured DataFrame is essential for training with Keras’ flow_from_dataframe method that we’ll use later in the tutorial.
1import pandas as pd
2
3# Set pandas to display full column content (no truncation)
4pd.set_option('display.max_colwidth', None)
5
6# Build (filepath, label) pairs from valid image paths
7data = []
8for path in valid_images:
9 label = path.parent.name # Extract label from directory name
10 data.append((str(path), label))
11
12# Create a DataFrame with columns for filepath and label
13df = pd.DataFrame(data, columns=["filepath", "label"])
14
15# Show a preview of the DataFrame
16df.head()
Step 2: Visualize the Data
2.1 Visualize the Class Distribution
Before training our CNN, it’s important to understand how many images we have for each class (i.e., coral species in this case).
In this step we:
Count how many images belong to each class
Plot the class distribution as a pie chart and bar graph
If the dataset is imbalanced (i.e., some classes have far more images than others), we may need to account for this later using class weights.
1import matplotlib.pyplot as plt
2
3# Count class distribution (counts how many times each unique value appears in the 'label' column of your DataFrame)
4counts = df['label'].value_counts()
5
6# Create a figure with two plots side-by-side (1-row, 2-columns; 12 inches wide, 5 inches tall)
7fig, axes = plt.subplots(1, 2, figsize=(12, 5))
8
9# Define a color palette
10colors = ['#8158ff', '#ff9423', '#7fcdbb']
11
12# Create a Pie chart in the first plot position (axes[0])
13## counts.values: The number of images for each class
14## counts.index: The class labels (e.g., 'ACER', 'CNAT', 'MCAV')
15## autopct='%1.1f%%': Display the percentage of images for each class
16## colors: The colors to use for each class (defined earlier)
17axes[0].pie(counts.values, labels=counts.index, autopct='%1.1f%%', colors=colors)
18axes[0].set_title('Class Distribution (Percentage)')
19
20# Creates a Bar chart in the second plot position (axes[1])
21axes[1].bar(counts.index, counts.values, color=colors)
22axes[1].set_title('Class Distribution (Values)')
23axes[1].set_ylabel('Number of Images')
24
25# Display the figure with both charts
26plt.show()
27
28# Print label counts and percentages
29for label, count in counts.items():
30 print(f"{label}: {count} images ({count/len(df)*100:1.2f}%)")
Thought Challenge: Describe the class distribution in your own words. How much of the dataset is made up by the largest class? The smallest class? Is there anything that we need to address before continuing?
2.2 Visualize Images from the Dataset
It’s helpful to look at a few images from each class to get a better understanding of the dataset. This will give us a better sense of:
What each coral species looks like
How much visual variation exists within each class (e.g., different angles, lighting, etc.)
Whether the dataset includes noise, blur, or other artifacts
We’ll display a grid of randomly selected images, grouped by class.
1from tensorflow.keras.preprocessing.image import load_img
2import random
3
4# Set the number of images to display per class
5samples_per_class = 3
6
7# Get list of unique coral species names (classes)
8classes = df['label'].unique()
9
10# Create a figure with appropriate size
11# The height (2.5 * len(classes)) ensures enough space for all images
12plt.figure(figsize=(12, len(classes) * 2.5))
13
14# Loop through each class to create a grid of images
15for i, label in enumerate(sorted(classes)):
16 # Filter DataFrame to get only images from the current class
17 class_df = df[df['label'] == label]
18
19 # Randomly select 3 images from the current class
20 sample_paths = random.sample(list(class_df['filepath']), samples_per_class)
21
22 # Create subplot for each image
23 for j, img_path in enumerate(sample_paths):
24
25 # Calculate position in grid: (row * width) + column + 1
26 plt.subplot(len(classes), samples_per_class, i * samples_per_class + j + 1)
27
28 # Load and display the image
29 img = load_img(img_path) # Load the image
30 plt.imshow(img) # Display the image
31 plt.title(label) # Add species name as title
32 plt.axis('off')
33
34plt.show()

Remember: the quality of a machine learning model is decided largely by the quality of the dataset it was trained on!
Step 3: Split the Dataset and Handle Class Imbalance
3.1 Split the Dataset into Training, Validation, and Test Sets
We are now ready to split our labeled image dataset into three parts:
Training Set: Used to train the model
Validation Set: Used to tune hyperparameters and monitor model performance during training
Test Set: Used to evaluate the final model’s performance after training is complete
We will use the train_test_split function from sklearn in two stages:
First, we split the original dataset into training + test sets
Then, we split the training set again into training + validation
This approach ensures that our CNN never sees the test set during training, which is important for obtaining an unbiased estimate of the model’s performance.
To preserve the class distribution across splits, we use stratify=df["label"] to ensure each split has the same proportion of each class as in the original dataset.
This is called stratified sampling.
1# NOTE: Replace the spaces indicated below with your code
2from sklearn.model_selection import ____
3
4# First, split the original dataset into training + test sets
5train_df, test_df = train_test_split(
6 df, # This is our DataFrame from step 1.5
7 test_size=____, # Keep 20% of the data in the test set
8 stratify=df["label"], # Ensure each split maintains original class distribution
9 random_state=123 # Set random seed for reproducibility
10)
11
12# Then, split the training set into training + validation sets
13____, ____ = train_test_split(
14 ____, # What goes here?
15 test_size=____, # Keep 20% of the training data in the validation set
16 stratify=____, # Ensure each split maintains original class distribution
17 random_state=123 # Set random seed for reproducibility
18)
19
20# Print split sizes
21total = len(df)
22print(f"\nDataset splits:")
23print(f"Train: {len(train_df)} images ({len(train_df)/total:.2%})")
24print(f"Validation: {len(val_df)} images ({len(val_df)/total:.2%})")
25print(f"Test: {len(test_df)} images ({len(test_df)/total:.2%})")
3.2 Compute Class Weights
If our dataset is imbalanced (i.e., some classes have many more images than others), the model may learn to favor those majority classes.
To address this, we can compute class weights based on the training data using the compute_class_weight function from sklearn.
These weights:
Assign higher importance to underrepresented classes
Are passed into
model.fit()using theclass_weightargumentAdjust how the loss is calculated during training
This technique helps the model give balanced attention to all classes during training.
While our dataset is quite balanced, we provide the code for computing class weights below:
1from sklearn.utils.class_weight import compute_class_weight
2import numpy as np
3
4# Get unique class labels
5class_labels = np.unique(train_df['label'])
6
7# Compute class weights based on training labels
8class_weights = compute_class_weight(
9 class_weight='balanced',
10 classes=class_labels,
11 y=train_df['label']
12)
13
14# Convert to a dictionary: {index: weight}
15class_weight_dict = dict(zip(range(len(class_labels)), class_weights))
16
17# Preview the result
18print("Computed class weights:")
19for index, weight in class_weight_dict.items():
20 print(f"{index}: {weight:.2f}")
Computed class weights:
0: 1.02
1: 1.08
2: 0.91
In the above output, 0 corresponds to ACER, 1 corresponds to CNAT, and 2 corresponds to MCAV. The class weights are inversely proportional to the number of samples in each class: classes with fewer samples get higher weights to compensate for their lower representation in the training data.
We need to convert the string labels (like ACER, CNAT, and MCAV) to integers (0, 1, 2) because the model expects numeric class indices. The class_weight_dict is a dictionary that maps each class index to its corresponding weight.
Thought Challenge: Look back at the pie chart and bar chart that we generated above. Do the class weights make sense? Why or why not?
The class weights make sense because the class with the fewest samples (CNAT) has the highest weight (1.08), while the class with the most samples (MCAV) has the lowest weight (0.91). This means that the model will pay more attention to the CNAT class during training, which has fewer samples.
Step 4: Image Preprocessing and Data Generators
As we discovered in Step 1.3, we need to prepare our images before feeding them into the CNN. This step involves two key concepts: Data Generators and Data Augmentation.
Data generators are special tools that help us efficiently load and preprocess image data in small batches (instead of all at once).
Keras provides a built-in data generator called ImageDataGenerator that can:
Resize all images to a consistent size
Normalize pixel values (e.g., from [0-255] to [0-1])
Augment the training data with random transformations to improve generalization
Data generators can be used with Keras model methods like fit(), evaluate(), and predict(), which is particularly useful when dealing with large datasets that don’t all fit into memory at once.
Data augmentation is a powerful technique that helps our model learn more robust features by creating variations of our training images. Augmentation techniques not only expand the size of our training set, but also help prevent overfitting by exposing our model to different variations of our images.
Conveniently, ImageDataGenerator also provides a number of built-in augmentation techniques that we can use to augment our training data, such as:
Random rotations
Zooming in or out
Shifting the image left or right
Flipping the image horizontally
Each of these modifications creates a new, slightly different version of our training images, helping our model learn to recognize the same features in different orientations.
4.1 Define Image Preprocessing and Augmentation
We will define three separate ImageDataGenerator objects, one for each dataset split (train, val, test):
train_datagenwill apply both normalization and augmentation to the training data
val_datagenandtest_datagenwill only apply normalization (no augmentation)
1from tensorflow.keras.preprocessing.image import ImageDataGenerator
2
3# Define training data generator
4train_datagen = ImageDataGenerator(
5 rescale=1./255, # Normalize pixel values to [0, 1]
6 rotation_range=30, # Augment: Random rotation
7 width_shift_range=0.2, # Augment: Random horizontal shift
8 height_shift_range=0.2, # Augment: Random vertical shift
9 zoom_range=0.2, # Augment: Random zoom
10 horizontal_flip=True, # Augment: Random horizontal flip
11 fill_mode='nearest' # Augment: After random transformations, fill in missing pixels with nearest neighbor
12)
13
14# Validation and test data generators only need normalization – do not augment
15val_datagen = ImageDataGenerator(rescale=1./255)
16test_datagen = ImageDataGenerator(rescale=1./255)
4.2 Load Images Using flow_from_dataframe()
Now that our preprocessing methods are defined, we can use flow_from_dataframe() to load images in batches directly from our labeled Dataframes (train_df, val_df, and test_df).
All generators return batches of preprocessed image tensors and their corresponding labels.
1# Set image size and batch size
2IMAGE_SIZE = (224, 224)
3BATCH_SIZE = 32
4
5# Training generator
6train_generator = train_datagen.flow_from_dataframe(
7 dataframe=train_df, # Our training DataFrame
8 x_col='filepath', # Column containing image paths
9 y_col='label', # Column containing labels
10 target_size=IMAGE_SIZE, # Resize images to this size
11 batch_size=BATCH_SIZE, # Number of images per batch
12 class_mode='categorical', # One-hot encode the labels
13 color_mode='rgb', # Use RGB color channels
14 shuffle=True, # Randomize order of images
15 seed=123 # Set random seed for reproducibility
16)
17
18# Validation generator
19val_generator = val_datagen.flow_from_dataframe(
20 # ... same parameters as above ...
21 shuffle=False, # Keep original order for validation
22 seed=123 # Set random seed for reproducibility
23)
24
25# Test generator
26test_generator = test_datagen.flow_from_dataframe(
27 # ... same parameters as above ...
28 shuffle=False, # Keep original order for testing
29 seed=123 # Set random seed for reproducibility
30)
Sanity Check: Inspect a Batch from the Training Generator
Let’s inspect the output of the train_generator to make sure it’s working as expected.
In the code below, we:
Retrieve one batch of images and labels from the training generator
Check the shape of the batch
Display a few image-label pairs to confirm the generator is working
1# Get one batch from the training generator
2images, labels = next(train_generator)
3
4# Check the shape of the batch
5print("Image batch shape:", images.shape) # Should be (BATCH_SIZE, height, width, channels)
6print("Label batch shape:", labels.shape) # Should be (BATCH_SIZE, num_classes)
7
8# Preview the first 5 label vectors
9print("\nFirst 5 labels (one-hot encoded):")
10print(labels[:5])
Visualize a Few Images from the Training Generator
Let’s display a few images from the training geneator along with their decoded class labels.
1# Get a fresh batch of images
2images, labels = next(train_generator)
3
4# Display 6 images in a grid
5plt.figure(figsize=(12, 6))
6
7# Show each image
8for i in range(6):
9 plt.subplot(2, 3, i + 1)
10
11 # Get the species name
12 species_names = list(train_generator.class_indices.keys())
13 species = species_names[np.argmax(labels[i])]
14
15 # Show the image
16 plt.imshow(images[i])
17 plt.title(f"Species: {species}")
18 plt.axis("off")
19
20plt.show()

Thought Challenge: Look carefully at the images displayed above. Try running the code cell multiple times and changing the code to display images from the validation and test generators. What do you notice about the images that you didn’t see before (in Step 3)? Do you notice any differences in the images each time you run the cell? Think about why this might be happening.
Step 5: Define Your CNN Model Architecture
Congratulations! Our data is now ready to be used to train a Convolutional Neural Network to classify our coral images.
In this step, we will define the architecture of our CNN model. Below, we define a model that consists of three main parts:
Convolutional Blocks (Feature Extraction):
Block 1: 32 filters (3x3 kernels), followed by Average Pooling
Block 2: 64 filters (3x3 kernels), followed by Average Pooling
Block 3: 128 filters (3x3 kernels), followed by Average Pooling
Each block increases the number of filters, allowing the model to learn increasingly complex features.
Flatten Layer: Converts the 3D feature maps into a 1D vector for the dense layers
Dense Layers (Classification):
First dense layer: 128 perceptrons
Second dense layer: 64 perceptrons
Output layer: How many perceptrons should our output layer have? Which activation function should we use?
1from tensorflow.keras import Sequential
2from tensorflow.keras.layers import Input, Conv2D, AveragePooling2D, Flatten, Dense
3
4# Build a custom CNN architecture
5cnn_model = Sequential([
6 # Input layer: matches image shape (height, width, channels)
7 Input(shape=(___, ___, __)),
8
9 # Convolution Block 1
10 Conv2D(32, (3, 3), padding='same', activation='relu'),
11 AveragePooling2D((2, 2), padding='same'),
12
13 # Convolution Block 2
14 # ...
15 # ...
16
17 # Convolution Block 3
18 # ...
19 # ...
20
21 # Flatten to convert 2D feature maps into a 1D vector
22 Flatten(),
23
24 # Fully connected layers
25 Dense(128, activation='relu'),
26 Dense(64, activation='relu'),
27 Dense(___, activation='___')
28])
Once you have filled in the blanks and defined your model, let’s compile it:
1from tensorflow.keras.optimizers import RMSprop
2
3cnn_model.compile(
4 optimizer=RMSprop(learning_rate=1e-4),
5 loss='categorical_crossentropy',
6 metrics=['accuracy']
7)
In the code above, we use the RMSprop optimizer, which adapts the learning rate based on recent gradients, and is a popular choice for image classification tasks.
We also set the learning rate to 1e-4, which sets the initial learning rate for the optimizer.
Note: While these are good starting choices, you might want to experiment with different optimizers or learning rates based on your model’s performance.
Finally, let’s display our model architecture and parameter count:
1cnn_model.summary()
Model: "sequential"
+--------------------------------+----------------------+-------------+
| Layer (type) | Output Shape | Param # |
+================================+======================+=============+
| conv2d (Conv2D) | (None, 224, 224, 32) | 896 |
+--------------------------------+----------------------+-------------+
| average_pooling2d | (None, 112, 112, 32) | 0 |
| (AveragePooling2D) | | |
+--------------------------------+----------------------+-------------+
| conv2d_1 (Conv2D) | (None, 112, 112, 64) | 18,496 |
+--------------------------------+----------------------+-------------+
| average_pooling2d_1 | (None, 56, 56, 64) | 0 |
| (AveragePooling2D) | | |
+--------------------------------+----------------------+-------------+
| conv2d_2 (Conv2D) | (None, 56, 56, 128) | 73,856 |
+--------------------------------+----------------------+-------------+
| average_pooling2d_2 | (None, 28, 28, 128) | 0 |
| (AveragePooling2D) | | |
+--------------------------------+----------------------+-------------+
| flatten (Flatten) | (None, 100352) | 0 |
+--------------------------------+----------------------+-------------+
| dense (Dense) | (None, 128) | 12,845,184 |
+--------------------------------+----------------------+-------------+
| dense_1 (Dense) | (None, 64) | 8,256 |
+--------------------------------+----------------------+-------------+
| dense_2 (Dense) | (None, 3) | 195 |
+--------------------------------+----------------------+-------------+
Total params: 12,946,883 (49.39 MB)
Trainable params: 12,946,883 (49.39 MB)
Non-trainable params: 0 (0.00 B)
Thought Challenge: Describe our CNN model architecture layer-by-layer.
First Convolutional Block
Input: 224 x 224 RGB images
conv2d: Creates 32 feature maps using 3x3 kernels -> Output shape maintains input size due to padding (224, 224, 32)average_pooling2d: Reduces spatial dimensions by half -> Output shape (112, 112, 32)
Second Convolutional Block
conv2d_1: Creates 64 feature maps using 3x3 kernels -> Output shape maintains input size due to padding (112, 112, 64)average_pooling2d_1: Reduces spatial dimensions by half -> Output shape (56, 56, 64)
Third Convolutional Block
conv2d_2: Creates 128 feature maps using 3x3 kernels -> Output shape maintains input size due to padding (56, 56, 128)average_pooling2d_2: Reduces spatial dimensions by half -> Output shape (28, 28, 128)
Classification Layers
flatten: Converts 3D feature maps into a 1D vector -> Output shape (100352)dense: First dense layer with 128 perceptronsdense_1: Second dense layer with 64 perceptronsdense_2: Output layer with 3 perceptrons (one for each coral species)
Calculating Parameters in CNNs
For a convolutional layer, the number of parameters is determined by the size of the kernels, the number of input channels, and the number of kernels:
Kernel width x Kernel height: The size of each kernel (e.g., a 3x3 kernel has 9 weights per input channel)Input channels: The number of channels in the input image (e.g., 3 for RGB images)+1: Each kernel also has 1 bias term.kernels: The number of kernels you want to use. This is how many output channels you’ll get from this layer. Each kernel is applied independently and learns different features.
Thought Challenge: What is the formula for calculating the number of parameters in a dense layer? Can you correctly calculate the total number of parameters in our model? Write down each step of your calculation.
Convolutional Layers
First Conv2D:
3x3 kernel, 3 input channels (RGB), 32 kernels
(3 x 3 x 3 + 1) x 32 = 896 parameters
Second Conv2D:
3x3 kernel, 32 input channels, 64 kernels
(3 x 3 x 32 + 1) x 64 = 18,496 parameters
Third Conv2D:
3x3 kernel, 64 input channels, 128 kernels
(3 x 3 x 64 + 1) x 128 = 73,856 parameters
Dense Layers
Formula: (Input units x Output units) + Output units
First Dense:
100352 Input units (flattened), 128 Output units (one per perceptron)
(100352 x 128) + 128 = 12,845,184 parameters
Second Dense:
128 Input units, 64 Output units
(128 x 64) + 64 = 8,256 parameters
Output Dense:
64 Input units, 3 Output units
(64 x 3) + 3 = 195 parameters
Step 6: Train the CNN Model
Now that our CNN architecture is defined, we can train the model using the fit() method.
During training, the model will learn patterns in the training data and adjust its parameters to minimize the loss function. After each epoch, the model’s performance is evaluated on the validation set.
Here, we will also pass in class_weight to demonstrate how to handle imbalanced data.
We also track the training history, which we’ll use later to visualize performance over time.
1cnn_history = cnn_model.fit(
2 train_generator,
3 validation_data=val_generator,
4 epochs=15,
5 class_weight=class_weight_dict # Computed in Step 3.2
6)
Example output:
Epoch 1/15
9/9 [==============================] - 5s 391ms/step - loss: 1.1136 - accuracy: 0.3195 - val_loss: 1.0908 - val_accuracy: 0.3731
Epoch 2/15
9/9 [==============================] - 4s 468ms/step - loss: 1.1017 - accuracy: 0.2932 - val_loss: 1.0911 - val_accuracy: 0.3582
Epoch 3/15
9/9 [==============================] - 4s 464ms/step - loss: 1.0936 - accuracy: 0.4023 - val_loss: 1.0823 - val_accuracy: 0.4627
Epoch 4/15
9/9 [==============================] - 4s 468ms/step - loss: 1.0937 - accuracy: 0.3534 - val_loss: 1.0762 - val_accuracy: 0.4328
Epoch 5/15
9/9 [==============================] - 4s 464ms/step - loss: 1.0869 - accuracy: 0.3985 - val_loss: 1.0671 - val_accuracy: 0.4627
...
Epoch 15/15
9/9 [==============================] - 4s 472ms/step - loss: 1.0374 - accuracy: 0.4662 - val_loss: 0.9806 - val_accuracy: 0.5672
Visualizing Training History
After training the model, we can visualize the accuracy and loss over time to better understand how the model is learning. These plots can help us identify overfitting, underfitting, or confirm that the model is learning as expected.
We use the cnn_history object returned by the fit() method to plot the training and validation accuracy and loss:
1def plot_training_history(history, title_prefix="CNN"):
2 acc = history.history['accuracy']
3 val_acc = history.history['val_accuracy']
4 loss = history.history['loss']
5 val_loss = history.history['val_loss']
6 epochs = range(1, len(acc) + 1)
7
8 # Set color palette
9 training_color = '#fc8d59'
10 validation_color = '#91bfdb'
11
12 # Plot accuracy
13 plt.figure(figsize=(14, 5))
14 plt.subplot(1, 2, 1)
15 plt.plot(epochs, acc, color=training_color, linestyle='-', marker='o',
16 label='Training Accuracy', linewidth=2)
17 plt.plot(epochs, val_acc, color=validation_color, linestyle='-', marker='s',
18 label='Validation Accuracy', linewidth=2)
19 plt.title(f'{title_prefix} Accuracy')
20 plt.xlabel('Epoch')
21 plt.ylabel('Accuracy')
22 plt.legend()
23 plt.grid(True, alpha=0.3)
24
25 # Plot loss
26 plt.subplot(1, 2, 2)
27 plt.plot(epochs, loss, color=training_color, linestyle='-', marker='o',
28 label='Training Loss', linewidth=2)
29 plt.plot(epochs, val_loss, color=validation_color, linestyle='-', marker='s',
30 label='Validation Loss', linewidth=2)
31 plt.title(f'{title_prefix} Loss')
32 plt.xlabel('Epoch')
33 plt.ylabel('Loss')
34 plt.legend()
35 plt.grid(True, alpha=0.3)
36
37 plt.tight_layout()
38 plt.show()
39
40# Call the plotting function
41plot_training_history(cnn_history)

The plots above show the training and validation accuracy/loss over 15 epochs.
Thought Challenge: What do you notice about the training and validation accuracy and loss? What does this tell you about the model’s learning performance (i.e. overfitting, underfitting, healthy learning)?
Step 7: Evaluate the Model on the Test Set
Now that we’ve trained our model, it’s time to evaluate its performance on the test set. This step is crucial because it helps us understand how well the model generalizes to new, unseen data, which is a good indicator of its real-world performance.
Evaluate Test Accuracy and Loss
We use model.evaluate() to calculate the test accuracy and loss. These metrics give us a quick overview of the model’s performance.
1# Evaluate test accuracy and loss
2test_loss, test_acc = cnn_model.evaluate(test_generator, verbose=0)
3print(f"Test Accuracy: {test_acc:.2%}")
4print(f"Test Loss: {test_loss:.4f}")
Example output:
Test Accuracy: 44.05%
Test Loss: 1.0581
Our model correctly classifies the test images about 35% of the time, and our loss is still quite high. While these numbers provide a snapshot of performance, they don’t tell the whole story. Let’s dig deeper with a confusion matrix.
Visualize Predictions with a Confusion Matrix
A confusion matrix provides a detailed breakdown of the model’s predictions compared to the true labels. It helps identify which classes are being confused with each other.
1from sklearn.metrics import confusion_matrix
2import seaborn as sns
3
4# Get predicted probabilities for each class
5pred_probs = cnn_model.predict(test_generator)
6
7# Convert to predicted class labels
8y_pred = np.argmax(pred_probs, axis=1)
9
10# Get true labels
11y_true = test_generator.classes
12
13# Create confusion matrix
14cm = confusion_matrix(y_true, y_pred)
15
16# Map class indices back to names
17class_names = list(test_generator.class_indices.keys())
18
19# Plot confusion matrix
20plt.figure(figsize=(8, 6))
21sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
22 xticklabels=class_names,
23 yticklabels=class_names)
24plt.title("Confusion Matrix")
25plt.xlabel("Predicted Label")
26plt.ylabel("True Label")
27plt.tight_layout()
28plt.show()

Detailed Performance with a Classification Report
The classification report provides precision, recall, and F1-scores for each class, offering a more nuanced view of model performance.
1from sklearn.metrics import classification_report
2
3# Print classification report
4print("Classification Report:")
5print(classification_report(y_true, y_pred, target_names=class_names))
Example output:
Classification Report:
precision recall f1-score support
ACER 0.50 0.52 0.51 27
CNAT 0.42 0.50 0.46 26
MCAV 0.40 0.32 0.36 31
accuracy 0.44 84
macro avg 0.44 0.45 0.44 84
weighted avg 0.44 0.44 0.44 84
Click below to see a brief explanation of the metrics in the classification report.
Precision: The ratio of correctly predicted positive observations to the total predicted positives.
Formula: \(\frac{\text{True Positives}}{\text{True Positives} + \text{False Positives}}\)
Interpretation: High precision indicates a low false positive rate, which is useful when the cost of false positives is high.
Recall: The ratio of correctly predicted positive observations to all actual positives.
Formula: \(\frac{\text{True Positives}}{\text{True Positives} + \text{False Negatives}}\)
Interpretation: High recall indicates a low false negative rate, which is useful when the cost of false negatives is high.
F1-score: The weighted average of precision and recall. It considers both false positives and false negatives.
Formula: \(2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}\)
Interpretation: The F1-score is useful when you need to balance precision and recall. It provides a single score that considers both false positives and false negatives.
Support: The number of actual occurrences of the class in the test data.
Thought Challenge: Critically assess the performance of our model based on the accuracy/loss values, confusion matrix, and classification report. Are there any classes that the model is particularly good or bad at predicting? Think about the data and why the model might be performing better or worse for certain classes.
Part 2: Transfer Learning with VGG19
In this section, we apply a technique called transfer learning to improve model performance on our coral species classification task.
Transfer learning is a deep learning technique where we reuse a model that has already been trained on a large dataset for a different but related task. Instead of starting from scratch, we “transfer” the knowledge learned by the pre-trained model to our new task.
This is especially useful when you have a limited dataset, you want to train a model faster, or you want to achieve better accuracy with less computational effort.
We will use the VGG19 model, a classic convolutional neural network architecture developed by researchers at Oxford University. It was trained on the ImageNet dataset, which contains over 14 million images across 1000 classes.
Step 1: Prepare Data for VGG19
1.1 Define Image Preprocessing and Augmentation
VGG19 expects input images to be preprocessed in a very specific way because of the way it was trained.
We use the preprocess_input() function from tensorflow.keras.applications.vgg19 to preprocess our images.
Specifically, this function converts RGB pixel values to the format VGG19 was originally trained on (i.e., channels in BGR order, zero-centered with respect to ImageNet).
Let’s create new data generators for VGG19 using ImageDataGenerator with:
preprocess_inputfor normalizationAugmentation on the training set
No augmentation on the validation and test sets
1from tensorflow.keras.applications.vgg19 import VGG19, preprocess_input
2from tensorflow.keras.preprocessing.image import ImageDataGenerator
3
4# Constraints
5IMAGE_SIZE = (224, 224)
6BATCH_SIZE = 32
7
8# Define new ImageDataGenerators for VGG19
9vgg19_train_datagen = ImageDataGenerator(
10 preprocessing_function=preprocess_input,
11 rotation_range=30,
12 width_shift_range=0.2,
13 height_shift_range=0.2,
14 zoom_range=0.2,
15 horizontal_flip=True,
16 fill_mode='nearest'
17)
18
19vgg19_val_datagen = ImageDataGenerator(preprocessing_function=preprocess_input)
20vgg19_test_datagen = ImageDataGenerator(preprocessing_function=preprocess_input)
1.2 Load Images Using flow_from_dataframe()
Just like we did for our CNN model, we can use flow_from_dataframe() to load images in batches directly from our labeled Dataframes (train_df, val_df, and test_df).
1# Assuming train_df, val_df, and test_df are defined
2# Create training generator below
3train_generator_vgg19 = _____
4
5# Create validation generator below
6val_generator_vgg19 = _____
7
8# Create test generator below
9test_generator_vgg19 = _____
Step 2: Define and Train the VGG19 Model
2.1 Load VGG19 Base Model and Stack a Custom Classifier
We now load the VGG19 base model, which has been pre-trained on ImageNet.
We exclude the original classification head (include_top=False) and freeze all convolutional layers.
Next, we stack a custom classifier on top using Keras’ Sequential API:
Flatten the output of VGG19’s last convolutional layer
Add the same fully connected (dense) layers that we had in our original CNN built from scratch
1from tensorflow.keras.applications import VGG19
2from tensorflow.keras import Sequential
3from tensorflow.keras.layers import ___, ___ # Import the necessary layers
4from tensorflow.keras.optimizers import RMSprop
5
6# Load VGG19 base (without top classifier)
7vgg_base = VGG19(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
8vgg_base.trainable = False # Freeze all pretrained layers
9
10# Build the full model
11VGG19_model = Sequential([
12 vgg_base,
13 # Add a flatten layer:
14 # ... your code here ...
15
16 # Then add our three dense layers:
17 # ... your code here ...
18 # ... your code here ...
19 # ... your code here ...
20])
Now, let’s compile the model with the same optimizer and loss function as our previous model.
1# Compile with a low learning rate optimizer
2VGG19_model.compile(
3 # ... your code here ...
4 # ... your code here ...
5 # ... your code here ...
6)
2.2 Define Training Callbacks
Next, let’s define some training callbacks. Callbacks are functions executed during training that allow the training process to change its behavior dynamically.
Some common callbacks include:
EarlyStopping: This callback stops training when a monitored metric (e.g., validation accuracy) stops improving. It helps prevent overfitting by halting training once the model’s performance plateaus.
ReduceLROnPlateau: This callback reduces the learning rate when a monitored metric (e.g., validation loss) stops improving. By lowering the learning rate, the model can converge to a better local minimum (preventing it from getting stuck in a suboptimal solution).
1from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
2
3# Define callbacks
4callbacks = [
5 EarlyStopping(
6 monitor='val_accuracy', # Monitor validation accuracy
7 patience=5, # Number of epochs to wait before stopping
8 restore_best_weights=True # Restore the best weights from the epoch with the highest validation accuracy
9 ),
10 ReduceLROnPlateau(
11 monitor='val_loss', # Monitor validation loss
12 factor=0.5, # Reduce learning rate by 50%
13 patience=3, # Number of epochs to wait before reducing learning rate
14 min_lr=1e-6 # Minimum learning rate
15 )
16]
17
18# Train the model with callbacks
19VGG19_history = VGG19_model.fit(
20 train_generator_vgg19,
21 validation_data=val_generator_vgg19,
22 epochs=15,
23 class_weight=class_weight_dict,
24 callbacks=callbacks # Pass the callbacks to the fit method
25)
Example Output:
Epoch 1/15
9/9 [==============================] - 7s 379ms/step - loss: 4.3120 - accuracy: 0.5263 - val_loss: 0.4430 - val_accuracy: 0.8657 - lr: 1.0000e-04
Epoch 2/15
9/9 [==============================] - 5s 503ms/step - loss: 0.7271 - accuracy: 0.8346 - val_loss: 0.3540 - val_accuracy: 0.9104 - lr: 1.0000e-04
Epoch 3/15
9/9 [==============================] - 4s 479ms/step - loss: 0.7825 - accuracy: 0.8120 - val_loss: 0.4158 - val_accuracy: 0.8507 - lr: 1.0000e-04
Epoch 4/15
9/9 [==============================] - 4s 480ms/step - loss: 0.4168 - accuracy: 0.8684 - val_loss: 0.3532 - val_accuracy: 0.8806 - lr: 1.0000e-04
Epoch 5/15
9/9 [==============================] - 4s 474ms/step - loss: 0.5239 - accuracy: 0.8835 - val_loss: 0.4578 - val_accuracy: 0.8806 - lr: 1.0000e-04
Epoch 6/15
9/9 [==============================] - 4s 470ms/step - loss: 0.4025 - accuracy: 0.8835 - val_loss: 1.0588 - val_accuracy: 0.8209 - lr: 1.0000e-04
Epoch 7/15
9/9 [==============================] - 4s 488ms/step - loss: 0.5346 - accuracy: 0.8496 - val_loss: 0.2890 - val_accuracy: 0.9104 - lr: 1.0000e-04
Visualizing Training History
Just like we did for our first CNN model, let’s plot the training and validation performance over time.
Refer back to Section 1: Step 6 – Visualizing Training History for a refresher on how to do this.
1# Plot for VGG19
2plot_training_history(VGG19_history, title_prefix='VGG19')

Thought Challenge: Compare the performance of our VGG19 model to our previous CNN model. What are some major differences in the training curves?
Step 3: Evaluate the VGG19 Model on the Test Set
Just like we did for our first CNN model, let’s evaluate the VGG19 model on the test set.
Evaluate Test Accuracy and Loss
First, let’s calculate the test accuracy and loss. Can you recall how to do this?
1# Evaluate test accuracy and loss
2# ... your code here ...
3# ... your code here ...
4# ... your code here ...
Example output:
Test Accuracy: 86.90%
Test Loss: 0.9072
Our model correctly classifies the test images about 87% of the time. What an improvement!
Visualize Predictions with a Confusion Matrix
Now, let’s visualize the predictions of our VGG19 model on the test set with a confusion matrix.
Refer back to Section 1: Step 7 – Visualize Predictions with a Confusion Matrix for a refresher on how to do this.
1# Get predicted probabilities for each class
2vgg19_pred_probs = # ... your code here ...
3
4# Convert to predicted class labels
5vgg19_y_pred = np.argmax(vgg19_pred_probs, axis=1)
6
7# Get true labels
8vgg19_y_true = # ... your code here ...
9
10# Create confusion matrix
11cm = # ... your code here ...
12
13# Map class indices back to names
14class_names = # ... your code here ...
15
16# Plot confusion matrix
17plt.figure(figsize=(8, 6))
18sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
19 xticklabels=class_names,
20 yticklabels=class_names)
21plt.title("Confusion Matrix")
22plt.xlabel("Predicted Label")
23plt.ylabel("True Label")
24plt.tight_layout()
25plt.show()
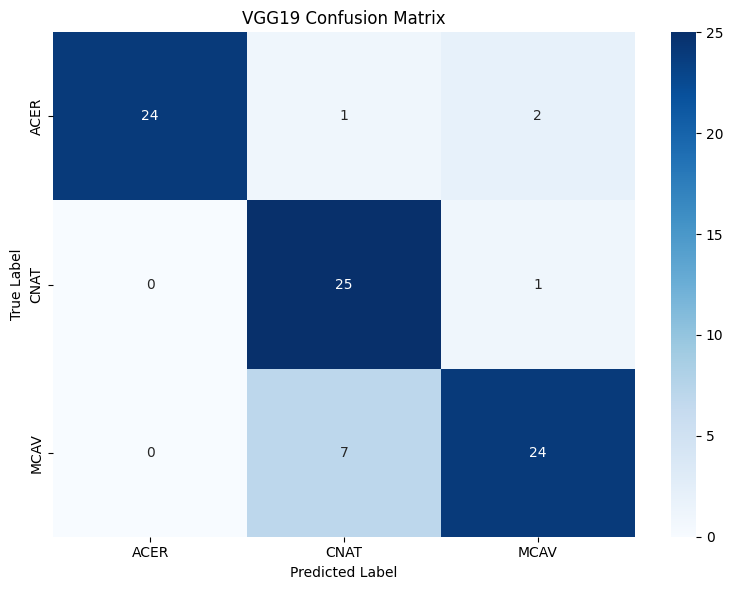
Notice how the confusion matrix shows a distinct diagonal pattern, where the true and predicted labels are the same more often than not? This indicates that our model is performing well on all classes. Nice!
Detailed Performance with a Classification Report
Finally, let’s print out the full classification report.
1# Print the full classification report
2# ... your code here ...
3# ... your code here ...
4# ... your code here ...
Example output:
Classification Report (VGG19):
precision recall f1-score support
ACER 1.00 0.89 0.94 27
CNAT 0.76 0.96 0.85 26
MCAV 0.89 0.77 0.83 31
accuracy 0.87 84
macro avg 0.88 0.87 0.87 84
weighted avg 0.88 0.87 0.87 84
Thought Challenge: Compare the performance of our VGG19 model to our previous CNN model. What are some major differences in the classification report? Are there still any problematic classes that the model is struggling with? If so, what do you think is causing this?
Step 4: Visualize Predictions from the Test Set
First, let’s take the raw predictions from our VGG19 model and organize them into a pandas DataFrame with four columns:
Filepath: Where each image is located
True Label: The actual species of coral in the image
Predicted Label: What our model thinks the species is
Confidence: How confident our model is in its prediction (0-1)
This organized DataFrame makes it easy to save our model’s predictions and create visualizations of the results.
1import os
2
3# Create a mapping from class indices to class names
4idx_to_class = {v: k for k, v in test_generator_vgg19.class_indices.items()}
5
6# The filenames already contain the full paths, so we can use them directly
7file_paths = test_generator_vgg19.filenames
8
9# Convert class indices to class names
10true_class_names = [idx_to_class[idx] for idx in vgg19_y_true]
11pred_class_names = [idx_to_class[idx] for idx in vgg19_y_pred]
12
13# Get the confidence scores for the predicted classes
14confidence_scores = [vgg19_pred_probs[i][pred_idx] for i, pred_idx in enumerate(vgg19_y_pred)]
15
16# Create the results DataFrame
17vgg19_results_df = pd.DataFrame({
18 'Filepath': file_paths,
19 'True Label': true_class_names,
20 'Predicted Label': pred_class_names,
21 'Confidence': confidence_scores
22})
23
24# Display first few rows
25print(vgg19_results_df.head())
Let’s display a few test images along with their predicted labels, true labels, and the model’s confidence scores.
This helps visually confirm whether predictions make sense – and helps identify patterns in misclassifications.
1from tensorflow.keras.preprocessing.image import load_img
2
3# Number of test images to show
4num_images = 8
5
6# Sample a few random rows from the test results
7sample_df = vgg19_results_df.sample(n=num_images, random_state=123).reset_index(drop=True)
8
9# Set up the plot grid
10plt.figure(figsize=(16, 8))
11for i in range(num_images):
12 row = sample_df.iloc[i]
13 img = load_img(row['Filepath'], target_size=(224, 224))
14
15 plt.subplot(2, num_images // 2, i + 1)
16 plt.imshow(img)
17 plt.axis('off')
18
19 # Determine color based on prediction accuracy
20 is_correct = row['Predicted Label'] == row['True Label']
21 color = 'green' if is_correct else 'red'
22
23 # Create title with colored text
24 title = f"Pred: {row['Predicted Label']}\nTrue: {row['True Label']}\nConf: {row['Confidence']:.2f}"
25 plt.title(title, fontsize=10, color=color)
26
27plt.suptitle("Sample Predictions", fontsize=12)
28plt.show()

Final Thoughts and Wrap-Up
Congratulations!
You have successfully built and trained a Convolutional Neural Network (CNN) using the VGG19 architecture to classify coral species.
You learned how to implement and utilize training callbacks to optimize the model’s performance.
You explored the importance of data preprocessing and augmentation in improving model accuracy.
You gained insights into the practical application of deep learning in biological data analysis.
To further enhance your model, consider the following ideas:
Fine-tune VGG19: Unfreeze some of the deeper convolutional layers and retrain the model to better adapt to your specific dataset.
Explore Other Architectures: Experiment with different pre-trained models like ResNet or Inception to compare their performance with VGG19.
Enhance Data Augmentation: Implement more aggressive data augmentation techniques such as color jitter, brightness shifts, cropping, and noise addition to increase model robustness.
Improve Image Quality: Apply image cleaning or filtering techniques to enhance the quality of your dataset.
Optimize Model Architecture: Consider adding Batch Normalization, Dropout, or other regularization techniques to improve model generalization.
—
Thank you for following along! You’ve made significant progress in understanding how deep learning can be applied to real-world biological data. Keep experimenting and learning!